I love designing, building, and managing reproducible, testable, and evolvable ML powered software.
When we develop a backend service for an application, we often do not think much about the underlying database connections that are used to read/write/modify data in the database. While a few database connections are not expensive, things start to change drastically when we scale up. So before we learn about what connection pooling is and how it can help us in building high performance systems, we need to understand how database connections work.
What are database connections?
Let's see what happens under the hood of this simple Python script which connects to a Postgres database and runs a simple query.
import psycopg2
conn = psycopg2.connect(
host="<hostname>",
port=<port>,
user="<username>",
password="<password>",
dbname="<database>",
)
cursor = conn.cursor()
cursor.execute("select * from artists where artist_id = '06HL4z0CvFAxyc27GXpf02';")
result = cursor.fetchall()
cursor.close()
conn.close()
Connecting to a database consists of multiple steps. To summarise, these are the operations that are performed:
- A database driver is used to open the connection
- A physical channel like socket (or named pipe) has to be established
- Initial handshake from the server occurs
- Connection is authenticated by the server
- Query/operation is completed
- Connection is closed
- Network socket is closed
So, opening and closing connections cost both computational resources and time.
Connection Pooling
In most cases, the connections that are opened and closed are identical for a given application. Connection pooling reduces the number of times a new database connection has to be opened by maintaining a collection (or pool) of connections which can be passed between database operations. By this method, we save on the costs of making new connections for each operation.
Experiment
I ran an experiment using a sample Postgres database hosted on railway.app.
First, I tried fetching 100 artists using their artist_id without using connection pooling. Next, I ran the same queries, but this time, instead of creating a new connection every time, I used psycopg2's SimpleConnectionPool.
The metrics which were logged are:
- Average time: The mean time taken by the 100 queries
- Maximum time: The longest query time
- Minimum time: The shortest query time
Without Connection Pooling
Code
import psycopg2
from data import ids
import time
def query_non_pool(a_id: str):
start_time = time.process_time()
conn = psycopg2.connect(
host="<host>",
port=<port>,
user="<user>",
password="<password>",
dbname="<dbname>",
)
cur = conn.cursor()
query = "select * from artists where artist_id = %s"
artist_id = (a_id,)
cur.execute(query, artist_id)
result = cur.fetchone()
end_time = time.process_time()
time_taken = end_time - start_time
cur.close()
conn.close()
return time_taken
time_samples = [query_non_pool(id) for id in ids]
print(
f"Average: {sum(time_samples)/len(time_samples)*1000} ms\nMax: {max(time_samples)*1000}ms\nMin: {min(time_samples)*1000}ms"
)
Result
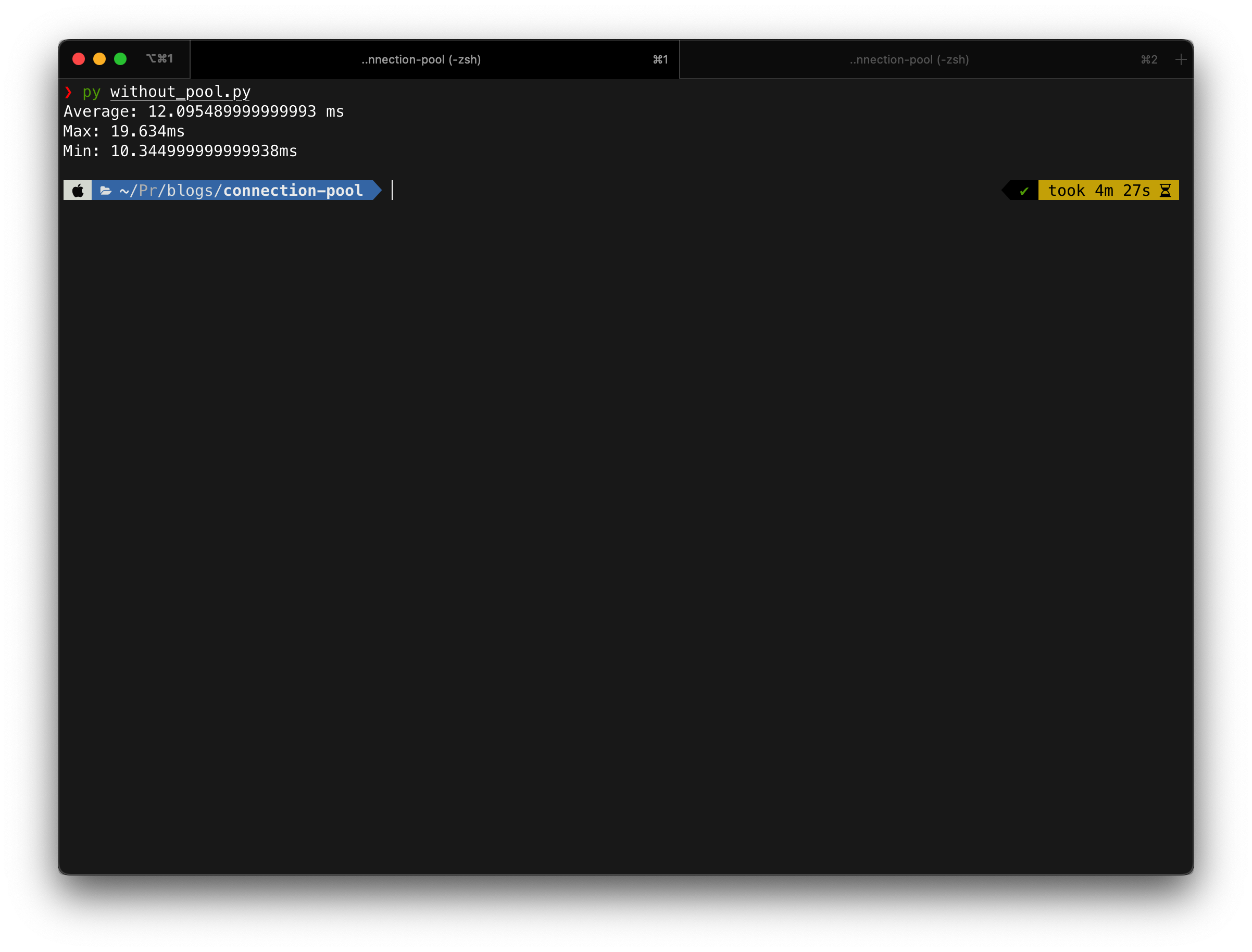
For a set of 100 queries, here are the results
Average taken per query: 12.09 ms
Maximum time taken: 19.63 ms
Minimum time taken: 10.334 ms
With Connection Pooling
Code
import psycopg2
from psycopg2 import pool
import time
from data import ids
# we define the min number of connections to be 1
# and maximum number of connections to be 50
conn_pool = pool.SimpleConnectionPool(
1,
50,
host="<host>",
port=<port>,
user="<user>",
password="<password>",
dbname="<dbname>",
)
def query_non_pool(a_id: str):
start_time = time.process_time()
conn = conn_pool.getconn()
cur = conn.cursor()
query = "select * from artists where artist_id = %s"
artist_id = (a_id,)
cur.execute(query, artist_id)
result = cur.fetchone()
end_time = time.process_time()
time_taken = end_time - start_time
cur.close()
conn_pool.putconn(conn)
return time_taken
time_samples = [query_non_pool(id) for id in ids]
print(
f"Average: {sum(time_samples)/len(time_samples)*1000} ms\nMax: {max(time_samples)*1000}ms\nMin: {min(time_samples)*1000}ms"
)
Result
For the same 100 queries, here are the results
Average time taken per query: 0.8 ms
Maximum time taken: 2.41 ms
Minimum time taken: 0.35 ms
Conclusion
Even though this might not be the most ideal testing condition, we see an improvement of 93.38% improvement in the average response time.
You can read more about connection pooling using psycopg2 here