A Beginner's Guide to gRPC: Faster, Smarter APIs

I love designing, building, and managing reproducible, testable, and evolvable ML powered software.
gRPC is a high-performance, open-source universal RPC (Remote Procedure Call) framework. It is developed by Google and provides efficient, low-latency communication between microservices. gRPC uses Protocol Buffers as the default data serialization format, but it also supports JSON as an alternative option.
But before we learn about gRPC, we should know the basics of its base technology: RPC
What is an RPC?
Let's say you have an e-commerce platform. There are two major operations or functions:
Cart/Order management
Payment System
The order management function invokes the payment system function. Both of them are on the same machine. But what if you want to have the two services on two different machines?
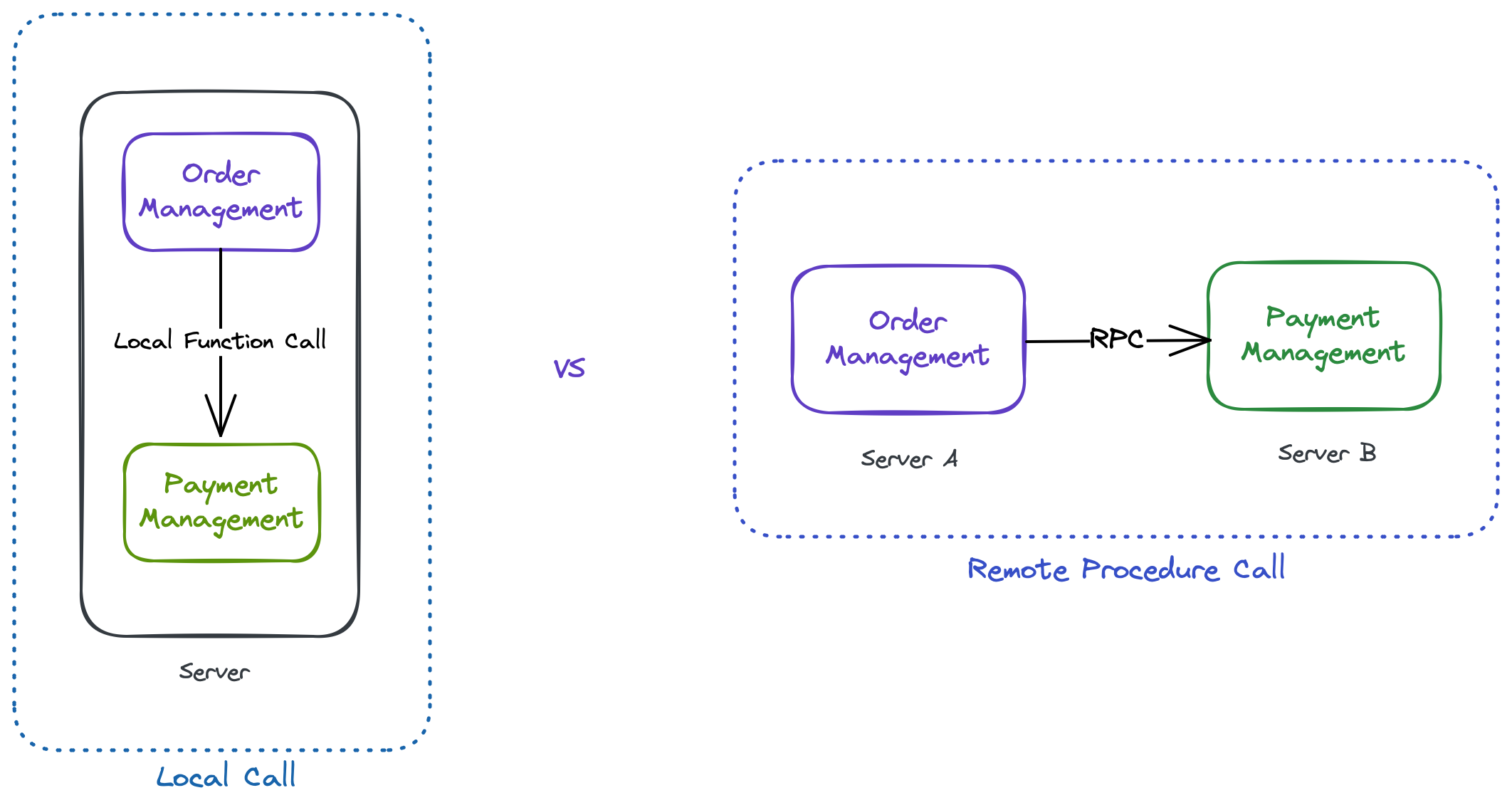
This is where we use something called a Remote Procedure Call or RPC. It allows code on one machine to invoke code on another machine as if it was on the same machine. The caller program does not need to know the details of the remote program's operation, only the inputs and outputs. This allows for more efficient and modular program design, as well as easier integration of distributed systems.
How does RPC work?
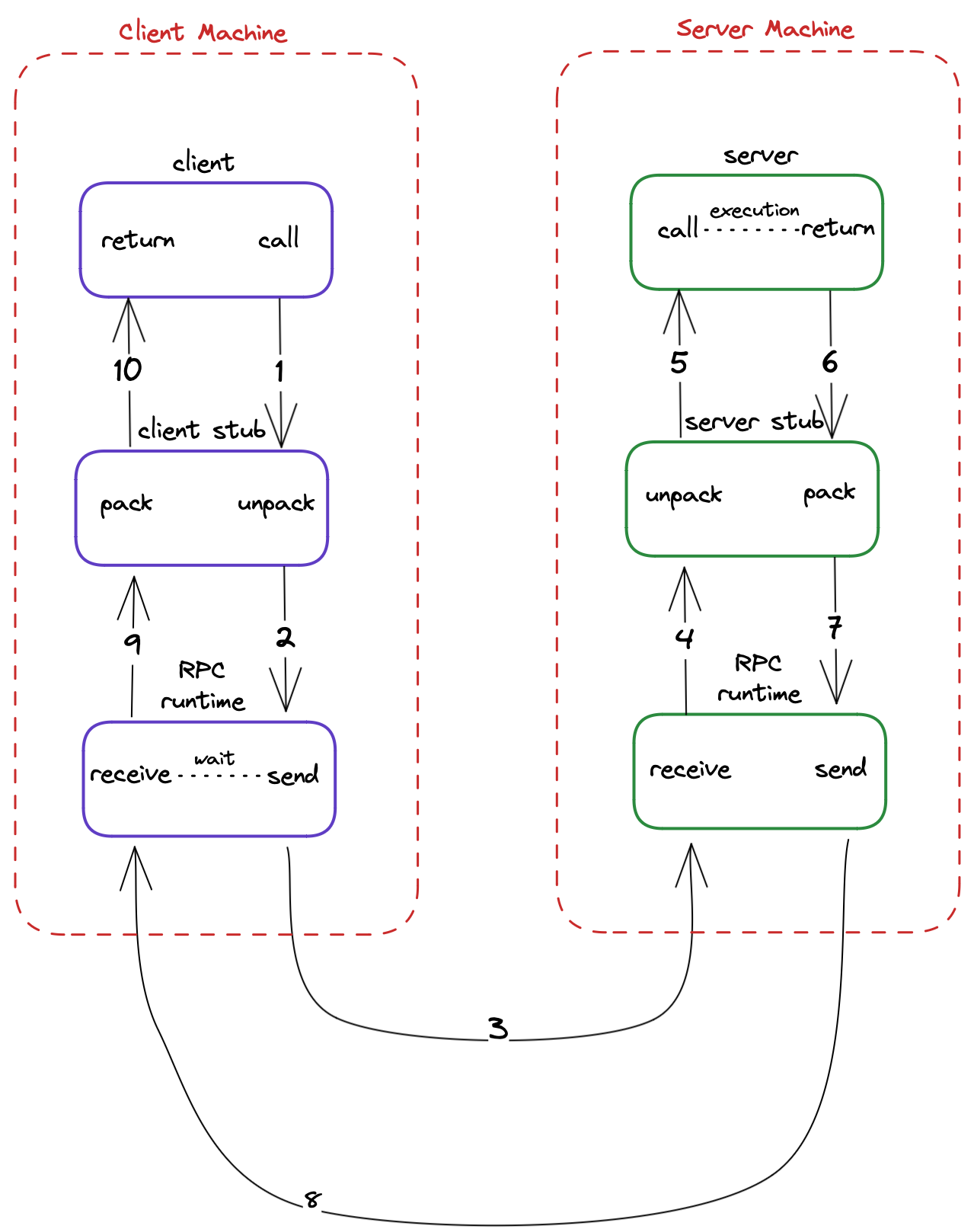
The client program invokes a local procedure (also known as a stub) that represents the remote procedure it wants to call.
The stub prepares the message to be sent over the network, which includes the procedure name, any input parameters, and the return address of the client program.
The message is transmitted over the network to the server program.
The server program receives the message and unpacks it to extract the procedure name and input parameters.
The server executes the procedure and returns the result to the client program, using the return address provided in the message.
The client program receives the result and continues with its execution.
Protobuf
Protocol Buffers, also known as protobuf, is a language-agnostic data serialization format. It is used to encode data in a compact binary format, which can then be transferred between applications or systems.
In gRPC, the client and server communicate using protocol buffer messages, which are defined in a protobuf schema file. The schema file specifies the structure of the message and the data types of its fields. This schema is then used to generate code in multiple programming languages, which provides a strongly-typed interface for working with gRPC messages.
syntax = "proto3";
message Artist {
string name = 1;
int32 age = 2;
repeated string genre = 3;
}
This schema defines a message called "Artist" that contains three fields: a string field called "name" with field tag 1, an integer field called "age" with field tag 2, and a repeated string (list of strings) field called "genre" with field tag 3.
The syntax = "proto3"; line specifies that this schema is written in Protobuf version 3. The message keyword is used to define a new message type, and the fields are defined using the string, int32, and repeated keywords to specify the field types and modifiers.
Using the protobuf as the serialization method for messages, we get faster processing and more efficient network usage. This is because it uses a binary format, which is more compact and requires less processing overhead compared to text-based formats like JSON.
Wait, but we already have REST?
If you're familiar with RESTful web services, you might be wondering why you should bother learning about gRPC. After all, REST has been the go-to choice for building APIs for a long time, and it's worked well for many use cases.
But as modern applications continue to grow in complexity and scale, there are some situations where gRPC might be a better fit than REST. Some of the reasons (that I am aware of, but there might be many more) are:
Data format: RPC uses binary data formats such as Protocol Buffers, Thrift, or MessagePack, while REST typically uses text-based formats such as JSON or XML. Binary formats are more compact and efficient to serialize and deserialize, resulting in fewer data to be transmitted over the network, and less processing required on the server and client side. This leads to faster communication between the client and the server.
Data transmission: RPC sends only the data required for the request, whereas REST transfers the entire representation of a resource. This means that REST can be slower than RPC when dealing with large payloads, such as when requesting or sending large files.
Caching: REST relies heavily on caching to improve performance. However, caching can be less effective if the response is not cacheable, or if the data changes frequently. RPC, on the other hand, does not rely on caching and can be faster for real-time and dynamic use cases.
Statelessness: REST is designed to be stateless, which means that the server does not store any client session data. While this makes REST scalable and easier to manage, it also means that the client has to include additional data in each request to maintain context, leading to more overhead. RPC can maintain the state between requests, allowing it to be faster in certain use cases.
However, the choice between RPC and REST ultimately depends on the specific use case and requirements of the application.
Wait, there's more!
Metadata: Metadata is a way to send additional information along with a gRPC request or response. Metadata can be used for authentication, tracing, or any other custom use case. Metadata is represented as a set of key-value pairs and can be accessed by both the client and server. This can be thought of as headers in an HTTP request.
Streaming: Streaming allows for bidirectional communication between the client and server. There are three types of streaming in gRPC: client-side streaming, server-side streaming and bi-directional streaming. With client-side streaming, the client sends multiple messages to the server and receives a single response. With server-side streaming, the server sends multiple responses to the client for a single request. Bi-directional streaming allows the client and server can send multiple messages to each other over a single gRPC connection.
Interceptors: Interceptors are middleware components that can be used to modify requests and responses in gRPC. Interceptors can be used for logging, monitoring, or any other custom use case. They can be applied to both the client and server and can be used to add, modify, or remove metadata from requests and responses.
Load balancing: gRPC provides built-in support for load balancing, which allows clients to connect to multiple instances of a server for improved scalability and reliability. gRPC load balancing can be performed both on the client and server side.
End of Part I
In this blog post, we have covered the basics of gRPC and its advantages over REST. We have also touched upon some advanced gRPC concepts such as metadata, streaming, interceptors, and load balancing. In the next part of this series, we will dive into the practical aspects of gRPC by setting up a Python environment for gRPC and building a simple request-response model. Stay tuned for more!
If you made it till here, here's an interesting fact. The 'g' in gRPC does not stand for Google. Its meaning changes with every release. Here is the Readme file which tracks the versions: https://github.com/grpc/grpc/blob/master/doc/g_stands_for.md